
Why agents fail
The thing about agents based on AI models is that right now, they are really bad at doing things. They can’t reliably do even basic addition and multiplication, let alone pilot a web browser. And this is not a problem that is going away any time soon.
While a lot of this has to do with aspects of how large language models work as a category of technology, there’s still a more fundamental issue at play about their basic mechanics. We’re gonna do a little bit of basic probability, but I promise it won’t be that bad.
If your chance of success at each step is , then the probability you are always successful for steps can be calculated using this formula:
For example, say you want to know what the chance of flipping a coin and having it come up heads every time, five times in a row.
Quite a rare event!
This is Bernoulli’s iron law: the law of large numbers. Over time, no matter how many times we try an inherently probabilistic process, we discover its true value: the true reliability of the task.
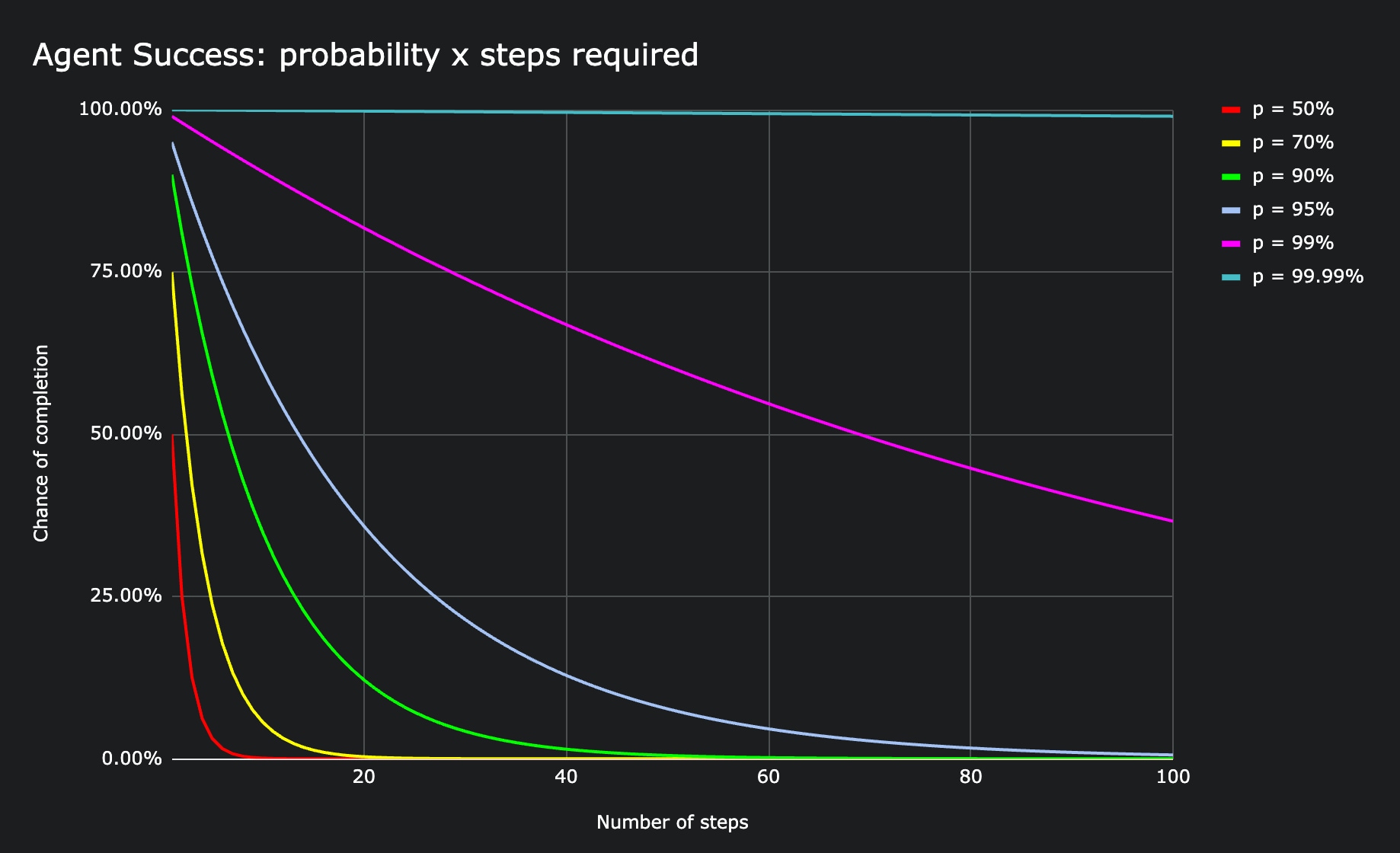
You can understand how the same basic principles can be applied to agents. When we give an agent a task and some starting conditions, we are hoping that it choses the correct action to take at every single step.
An agent that chooses the correct step 90% of the time — and I gotta say, if you have an agent like this, please contact us because you’ve made a fundamental breakthrough — has a 59.05% chance of completing a five step task. And at ten steps we’re looking at success rate of 34.87%.
In the context of web agents, this means that even if the three-click rule holds true, the true success rate of that agent is more like 72.90%.
Software that only works 72.90%, 95%, or even 99% of the time is bad software. It is too unreliable to use. Reliability is measured in the number of nines. For example, AWS’s S3 has 11 nines. That is 99.999999999% reliability. In practice this means if you store 10,000 objects, you will only lose one once every 10 million years [1].
In order to elevate agents to production, they need to be basically perfect every time. This is why we see a lot of agent companies, but few agents actually in production.
When to (not) be agentic
Our solution is simple: reduce the probabilistic action space. We can still retain a lot of fundamental technology — falling back to models for exploring and reasoning about next potential actions — but by being clever with search and embedding, we can substitute in known actions as a kind of “guard rail” over a task.
Let’s work with an example.
How many steps are involved in booking a hotel? Really simply: we aren’t even researching prices. We’re just booking the hotel.
- You’ll visit the hotel homepage.
- You’ll see something like a ‘Book now’ button and click it.
- You may need to pick a type of room, and hit ‘search’.
- You’ll see a calendar with dates and select the start and end dates.
- You’ll see an estimation of the price, potential upsells, etc.
- You’ll enter a payment flow. Optionally, you’ll be prompted to enter in details for a rewards program or something like that.
You can guess that while the details might differ, hotel websites don’t structurally differ all that much. And if we know the objective, and we can create a structure of the page content — leveraging accessibility tools in the process — we can take out a whole bunch of these steps. You may need the model for reasoning — what dates matter for us? What are the payment details to input? — we can substitute out most of these steps, leaving the new content and the state-specific reasoning to a model.
Our approach is based on our Collective Memory Index, a search index over web trajectories and actions. If you’d like to experiment with it, we invite you to learn more at hdr.is/memory and get on the waitlist to use it with our agentic web automation framework, Nolita.
[1] https://aws.amazon.com/blogs/aws/new-amazon-s3-reduced-redundancy-storage-rrs/